
האם צריכים להיות נחמדים לבינה מלאכותית?
מחמאות, איומים ומה שביניהם
מפעם לפעם עולה השאלה, האם אנחנו צריכים להיות נחמדים לכלי הבינה המלאכותית איתם אנחנו מבצעים שיחות? האם איכות התשובה באמת משתפרת? האם אני אקבל דרך מחמאות מקורות מידע מהימנים יותר או האם ב״יום הדין״ כאשר המכונות ישתלטו על העולם הם יזכרו אתכם לטובה?
כל אלו שאלות טובות, אבל השאלות האלה מגיעות גם מכיוון קצת אחר, למשל: האם איומים והפחדות יכולים לסייע לנו מול בינה מלאכותית? אם נמאס לי מהשטויות וההזיות קצת ׳קשיחות׳ יכולה לעזור?
בואו ננסה לענות על השאלות האלה במאמר הבא:
רק לפני כמה חודשים לעג סם אלטמן, מנכ״ל Open AI על הנטייה של אנשים לכתוב ל-ChatGPT מילים כמו ״תודה״ או ״בבקשה״ בפרומפטים שהם מנסחים. בתשובה לפוסט ברשת החברתית X הוא ציין שזה פשוט מבזבז כוח מחשוב בשווי של ״עשרות מיליוני דולרים״.
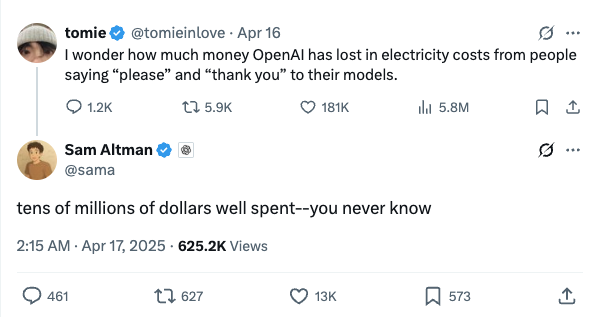
אז נכון, אנחנו לא יודעים אם סם אלטמן התבדח או לא, אנחנו גם לא יודעים או זו עוד ה׳טרלה׳ מבית היוצר של מייסד OpenAI, אבל בואו ננסה בכל זאת לצלול טיפה יותר עמוק כדי לנסות לענות על השאלה הזו לעומק.
בפברואר 2024, פורסם ביפן מחקר בשם ״Should we respect LLMs״, אשר שם לנגד עיניו מטרה לבחון כיצד רמות נימוס שונות בפרומפטים משפיעות על ביצועי LLM (מודלי שפה גדולים) בשלוש שפות - אנגלית, סינית ויפנית. למעשה, החוקרים יצרו גרסאות של אותם פרומפטים בארבע דרגות שונות: לא מנומס (רודני), ניטרלי, מנומס ומאוד מנומס. ומה תוצאות המחקר אומרות?
- פרומפטים שנכתבו בצורה שאינה מנומסת - הורידו ביצועים בעקביות בכל השפות והמשימות.
- נימוס מתון ולא מוגזם - שיפר את התוצאה הממוצעת.
- עודף נימוס - לא נתן ״בונוס״ נוסף לאיכות התשובה, ולעיתים אף פגע בביצועי מודל השפה.
אגב, סתם ככה כבונוס וזווית נוספת על המחקר, נראה כי נקודת האיזון בין הדרגות משתנה בהתאם לשפה ולתרבות. בעצם, מה שנחשב ״מנומס מספיק״ באנגלית אינו בהכרח נכון ביפנית או בסינית כך שאנחנו מבינים שכלי AI משתנים באיכות התשובה בהתאם להקשר התרבותי.
אז למה זה משפיע?
מספר מסקנות עיקריות עולם מהמחקר, כאשר החוקרים מציינים:
- מודלי שפה גדולים משקפים דפוסים חברתיים בנתוני האימון שלהם ולכן מגיבים לנורמות תרבותיות של נימוס. במילים אחרות, בגלל שמודלי השפה מאומנים על מידע מאתרים שבהם נימוס בסיסי הוא ברירת מחדל (ויקיפדיה, ספרים, מאמרים ועוד) - הם מחזקים יותר תשובות אדיבות ובלתי מזיקות.
- הטון משפיע על אלגוריתם החיזוי הסטטיסטי, לא מפני שהוא ״נעלב״, אלא מפני שהמילים מגדירות הקשר שפתי-תרבותי.
ממה כדאי להימנע?
החוקרים מציינים כמה דברים שכדאי להימנע מהם ובכלל המלצות יישומיות שכדאי לקחת בחשבון כאשר אתם כותבים פרומפטים למודלי השפה:
- הימנעו מעוינות או איומים - החוקרים מציגים כי איומים, מילים קשות או עוינות כמעט תמיד פוגעת באיכות התשובה.
- ניסוח בנימוס ענייני - במילים פשוטות החוקרים מציגים לנו כי כדאי להשתמש בנימוס, אבל מצד שני לא להגזים כי אין שום השפעה על איכות התוצר. לכן, אל תנסו להשתפך עם מילות נימוס מוגזמות או האדרה שאינה לצורך.
- התאמה תרבותית - המחקר מציג כי המילה ״בבקשה״ מספיקה כאשר כותבים פרומפטים באנגלית, אבל כאשר אתם מתנסחים ביפנית או סינית, צריך וכדאי להשתמש יותר בתארים בפורמולות נימוס מקובלות חברתית ותרבותית.
- בדיקות A/B - החוקרים מציעים לנו להשתדל ולבדוק את הפרומפטים שלנו בהקשר של רמת הנימוס האופטימלית לטובת משימה. לכן, שווה לבדוק את איכות התשובות שאתם מקבלים כאשר אתם ״מנומסים״ לעומת תשובות שקיבלת כאשר ״אינכם מנומסים״ למכונה.
שורה תחתונה
אז כן, יש לכם תועלת בפרומפטים שמנוסחים בצורה ״חיובית״, אבל במינון נכון. כאשר משתמשים בטון מתאים וענייני ובהקשר התרבותי הנכון ניתן לשפר את איכות התשובות המתקבלות ממודלי השפה, בעוד שגסות רוח מורידה אותן ו״נימוס יתר״ לא מביא לערך מוסף.
ומן הצד השני, מה קורה כאשר אנחנו מאיימים על בינה מלאכותית או משתמשים בשפה שלילית?
אז רק לא מזמן, סרגיי בריין, אחד ממייסדי גוגל - התבטא במהלך אירוע שהתרחש במאי 2025 ונקרא "All-In Live" במיאמי, ש״מודלי בינה מלאכותית מגיבים טוב יותר לאיומים מאשר לנימוס״.
בהמשך הוא גם ציין כי ״אנחנו לא מפיצים את זה יותר מדי בקהילת הבינה המלאכותית - לא רק המודלים שלנו, אלא כל המודלים - נוטים להגיב טוב יותר אם מאיימים עליהם…באלימות פיזית. אבל…אנשים מרגישים מוזר עם זה, אז אנחנו לא באמת מדברים על זה״. הוא המשיך ואמר ״אתה פשוט אומר למודל ׳אני אחטוף אותך אם לא תעשה כך וכך…״.
Sergey Brin, Google Co-Founder | All-In Live from Miami (8:15)
הגישה הזו, בה אנו יכולים וצריכים להתעמר או לדבר בצורה ״לא יפה״ לבינה מלאכותית על מנת לקבל תשובות טובות יותר, שמה בסימן שאלה מסוים את המחקר אותו הצגנו בתחילת הכתבה. קשה להתעלם מכך שגישות שונות כל כך מביאות לתוצאות מנוגדות.
לצד הגישה של ברין לנושא, נראה שיש גם מספר מחקרים ומאמרים שפורסמו בנושא שתומכים בגישה הזו, למשל מחקר בשם ״NegativePrompt: Leveraging Psychology for Large Language Models Enhancement via Negative Emotional Stimuli״ שפורסם במאי 2024.
על פי המחקר (גילוי נאות - המחקר טרם זכה לפרסום בכתב עת רשמי) נתנו לחמישה מודלי שפה (LLM's) כמו GPT-4 ו-Llama 2 שתי סוגים של משימות. משימה מסוג Instruction Induction אשר נועדו לבחון את יכולתם של מודלי שפה גדולים להסיק משימות/תשובות בסיסיות מתוך הדגמות פשוטות וישירות, למשל: איות, תחביר, ידע, סמנטיקה ועוד. סוג המשימות השני היה משימות מסוג Big Bench שהן משימות הנחשבות למאתגרות ומורכבות יותר, כמו למשל: חידות בלשניות, פרשנות, ספירת אובייקטים, מיון מילים, זיהוי כשלים לוגיים ועוד.
תוצאות המחקר
על פי המחקר, נמצא כי פרומפטים שליליים שיפרו באופן נכיר את ביצועי מודלי השפה בשני סוגי המשימות:
- שיפור יחסי של כמעט 13% במשימות Instruction Induction
- שיפור מרשים של 46.25% במשימות Big Bench
- רגשות אשר מעוררים דיסוננס אישי (״בושה״, ״אשמה״) סיפקו את התמריץ החזק ביותר. רגשות כמו ״כעס״ היו מועילים אך פחות דרמטיים.
שורה תחתונה
אז איך לנסח את הפרומפטים שלנו? האם פרומפט צריך להיות חיובי? האם הוא צריך להיות שלילי?
בשורה התחתונה, ניתן לומר שיש השפעות מגוונות לפרומפטים חיוביים ולפרומפטים שליליים על איכות התשובה שנקבל ממודלי השפה. נראה שעל פי המחקרים השונים והגישות השונות שיש איזשהו מקום באמצע שאנחנו צריכים להכיר ולקחת בחשבון כאשר אנחנו כותבים פרומפט.
אז כן, יש עליה באיכות התשובה כאשר משתמשים בפרומפטים חיוביים.
וכן, יש גם עלייה באיכות התשובה כאשר אנחנו משתמשים בפרומפטים שליליים.
אבל מה שחשוב באמת זה לתרגל כתיבת פרומפטים בצורות שונות על מנת לבחון את איכות המודלים והדרך שבה הם מגיבים לשפה בה אנחנו משתמשים.